Friday, 24. November 2006
"Eine, der Erfahrungen, die ich hierbei machen konnte, besteht in der Erkenntnis, daß das Verständnis von APL höhere intellektuelle Anforderungen stellt als das Verständnis anderer Sprachen."
Das mein Wolfgang Janko, ein veritabler Professor und Buchautor (APL 1, APL 2/I, APL 2/II u.a.). Wenn er das so schreibt, dann muss das wohl stimmen. Also dürfen wir uns getrost als Hoch-Intelligenzler bezeichnen, wenn wir es verstehen mit APL Probleme zu lösen? APL als Messlatte für Intelligenz, gar als Komponente eines IQ-Tests?
Nein, darauf möchte ich mich nicht einlassen. Ich bin allerdings überzeugt, es hilft in Strukturen denken zu können. Ansonsten wird man die Stärken von APL nicht vollständig schätzen können und möglicherweise jede Schleife, die in Basic geschrieben werden muss auch in APL schreiben.
Jankos Erkenntnis stammt aus dem Jahre 1981 und war zu lesen in der Computerwoche als Teil einer Kritik an einen CW-Artikel. Passend der Titel: " Intellektuelle lösen Algorithmen mit APL", eine Aussage, die dem Ruf von APL und seinen Protagonisten sicher nicht zuträglich war.
"Wir Intelligenzbestien" vollständig lesen
Es ist nun fast 40 Jahre her, dass das erste mal ein "CLEAR WS" auf einem Rechner angelegt wurde. Jedes IBM-APL erinnert mit dem Pseudo-WS CLEANSPACE (was ist bloß falsch an diesem WS-Namen) an den genauen Zeitpunkt dieses Ereignisse:
)LOAD 1 CLEANSPACE
SAVED 1966-11-27 23.53.59 (GMT+1)
Nun treibt es mich schon seit Monaten um, warum jetzt unbedingt die 40. Wiederkehr dieses Tages gefeiert werden muss. Denn ich habe erst meinen 50. Geburtstag mit großem Brimborium begangen. Zugegebenermaßen habe ich den 30. und den 40. mehr beachtet als die Jahrestage dazwischen.
Rein zahlentechnisch ist die 40 nicht sehr imposant. Sie ist im Dezimalsystem so gut wie die 30, 20 oder 60. Wir dezimal denkenden Menschen (es gibt Menschen, die in anderen Stellenwertsystemen denken) legen ganz gesonderten Wert auf die 50 oder 25 und 75: ein halbes Jahrhundert, ein viertel oder dreiviertel Jahrhundert. Die 40 ist mal gerade ein zweikommafünftel Jahrhundert.
Warum also gerade im Falle von APL den 40. Geburtstag groß feiern? Haben wir Angst, dass wir den 50. nicht mehr erleben? Oder weil wir APLer Zahlen aus der Sicht eines Waschbären betrachten - im Oktalsystem, wegen der 8 Finger, vier an jeder Pfote? Hier sind 40 Dezimaljahre 50 Oktaljahre, also tatsächlich ein halbes Jahrhundert.
Nein, wir sind keine Waschbären. Die Antwort ist natürlich im Computer zu finden: Wir stellen für den Rechner Zahlen gerne und oft im Hexadezimalsystem dar, und da ist unsere dezimal 40 hexadezimal eben die 25, ein viertel Jahrhundert, ein Silberjubiläum.
Es gibt Leute, denen wäre das alles so oder so egal: Die würden erst das 42. Jubiläum feiern.
Thursday, 23. November 2006
Beim Stöbern durch uralte CW-Artikel, die die drei Buchstaben "APL" in dieser Reihenfolge beinhalten, habe ich einen Lobgesang von IBM auf APL gefunden - aus dem Jahre 1980. Das passiert denen heute bestimmt nicht mehr. Hier die Höhepunkte:
"Das heutige IBM-Angebot setzt die Kendallsche Tradition (erheblich erweitert) fort; APL - A Programming Language - ist immer dabei."
Das waren noch Zeiten! Good old Big Blue.
"Das allgegenwärtige APL, einsetzbar auf /370-, 43XX- und 303X-Systemen, offeriert IBM als "klare Sprache"; denn "die Integration aller Benutzer innerhalb eines Unternehmens erfordert" eben eine solche."
In Sachen "klare Sprache" in Sinne von klarer, mathematischer Struktur bin ich da ganz auf Seiten der IBM von 1980. Für die IBM der Gegenwart ist Java die "klare Sprache". Welch ein Fortschritt: Tausende Programmierer, die Tonnen von buggy Spagetti-Code produzieren. Klar ist hier nur, dass diese Codemassen jeden Fortschritt in der Hardware kompensierten.
Meine alten APL-Funktionen performen inzwischen fast so schnell wie das Licht. Hier kann ich Ernte der Realisierung des "Moorschen Gesetzes" einfahren, nicht so bei Word und Konsorten (ich sollte hier DB2 explizit aus der Kritik heraus halten). APL ist kompakt, Java ist objektorientiert, C ist weder das eine noch da andere.
Weiter im Text mit Staunen:
Auf der Suche nach meinem ersten APL-Buch habe ich einige sehr alte CW-Artikel zu APL gefunden. Ende 1981, wahrscheinlich im November, lieh ich mir zur Vorbereitung auf meinen Job als Systemanalytiker "APL 1" von Wolfgang Janko in der UB Düsseldorf aus. Das Buch musste ich natürlich wieder zurückgeben, den gelesenen Stoff habe ich behalten.
Das Buch habe ich in der Zwischenzeit nicht mehr in der Hand gehabt. Nach 25 Jahren meine ich, dass es mir fehlt. Also googlete ich nach "Janko APL" und fand einen CW-Artikel aus dem Jahre 1982. APL und 1982, da war doch was? Tatsächlich tanzte in diesem Jahr der APL-Kongress in Heidelberg und Janko war der Vortänzer. In besagtem Artikel kamen also anlässlich dieses Ereignisses einige Mitglieder des Organisationskommitees zu Worte.
Und dabei kamen interessante Aussagen heraus. Ich zitiere aus dem CW-Artikel " APL als Sprache für Manager entdeckt", übrigens ein Titel, der zum Lästern geradezu auffordert.
"APL, benannt nach dem vor 20 Jahren erschienenen Buch "A Programming Language" von Kenneth E. Iverson, hat nach Überzeugung der Kongreßveranstalter Zukunft." Das können wir heute nach 24 Jahren beurteilen. Ich bin überzeugt, dass APL immer noch eine Zukunft haben müsste, wenn die IT-Menschheit einigermaßen vernünftig strukturiert wäre.
Wednesday, 22. November 2006
... dass eine DB2-Datenbank erst für Data Mining vorbereitet werden muss, um Data-Mining-Algorithmen auf die Tabellen der Datenbank ausführen zu können.
Richtig ist auch, dass dies mit einem einfachen Befehl im DB2-Befehlsfenster geschehen kann. So beschrieben im der DWE-Hilfe oder im DWE-Tutorial (S.82).
Er ist glücklicherweise falsch, dass dies im Design Studio nicht durch eine Option in einem Kontextmenu unterstützt wird. Diese findet man zwar nicht im Datenprojektexplorer - wie bereits bemerkt -, sondern unter links im Datenbankexplorer:
Einfach die Verbindung zur vorzubereitende Datenbank herstellen, den entsprechenden Datentenbank-Ordner öffnen, per rechtem Mausklick auf das blaue Plattensymbol (oder auf den darauf folgenden Datenbanknamen) das Kontextmenü öffnen und die Option "Datenbank für Data Mining aktivieren".
Es ist weiterhin richtig, dass das Vorbereiten einer Datenbank - genauer: eines Datenbankmodells - für OLAP im Datenprojektexplorer angeboten wird: rechter Mausklick auf eine Datenbank unter "Datenbanken", Option "OLAP-Objekte implementieren".
Sunday, 12. November 2006
Da war ich doch etwas voreilig mit meinem Wunsch nach einer Möglichkeit, Mining-Modelle im Design Studio zu verwalten.
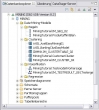 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Und nicht nur das: Ein rechter Mausklick auf ein Modell öffnet ein Menü mit den Einträgen "Öffnen", "Löschen", "Umbenennen" und "Exportieren".
Sunday, 29. October 2006
Noch mehr zum Thema " Jeder Fluss ist anders".
Gleicher Namen heißt nicht gleicher Inhalt. Das gilt auf jeder Fall für den Tabellenziel-Operator im Daten- und im Mining-Fluss.
In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE.
Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".
Diese Option wäre IMO auch für den gleichnamigen Operator im Daten-Fluss sinnvoll. Dann muss ich nicht im Falle eines Inserts bereits exsistierende Daten explizit per Operator löschen. Dies würde unter Umständen zur Synchronisation sogar einen Steuerungs-Fluss erfordern.
Dafür könnte im Gegenzug der Operator im Mining-Fluss die Check-Box "NOT LOGGED INITIALLY" erhalten oder gar den Tab "Zuordnen". Give 'n Take.
Von Mining-Operatoren wie z.B. dem "Clusterer" werden automatisch Mining-Modelle erstellt und in der Datenbank gespeichert. So ein Modell kann dann im Scorer ausgewählt werden. Bei dieser Auswahl kann man dann sehen, welche Modelle überhaupt erstellt wurden. Da war dann in meinem Fall noch das eine oder andere experimentelle Modell darunter.
Nur, wo kann ich solche nicht verwendete Modelle löschen. Oder allgemeiner: Wo kann ich Mining-Modelle verwalten?
Einfache Frage, einfache Antwort: In der Ausführungsdatenbank und dort in der Tabelle IDMMX.CLUSTERMODELS. Dies ist übrigens eine der Tabellen, die beim " Enable for Data Mining" angelegt werden.
Zur Verwaltung der Modelle steht also der komplette SQL-Funktionsumfang zur Verfügung.
Trotz alles SQL-Möglichkeiten wäre es sicher sinnvoll, wenn Mining-Modelle direkt im Design Studio in bewährter Art und Weise verwaltet werden könnten (23.11.2006: was auch tatsächlich angeboten wird, wenn auch an etwas unerwarteter Stelle).
Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Eine der hilfreichsten von vielen nützlichen Funktionen im Design Studio ist "In Modell speichern". Sie ist jeweils unter "Virtuelle Tabelle" in den Eigenschaften der Ein- und Ausgabeports verfügbar. So kann ganz einfach eine durch einen Operator erstellte Ausgabe sofort im Modell als Tabelle widerspiegelt werden. Diese Tabelle kann ich dann z.B. als Tabellenziel am Ende des Flusses verwenden.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Um das alles ein wenig abzukürzen: Im Falle des Scorer geht das schief.
"Schiefgagangen" vollständig lesen
Hier sind zwei der Kleinigkeiten, die mir das Entwickeln eines Minig-Flusses erleichtern:
Friday, 27. October 2006
Ein Fluss muss nicht wie der andere sein.
Zumindest ist das im Design Studio recht offensichtlich. Hat man einige Datenflüsse und Minig-Flüsse erstellt, sieht man recht schnell, dass dahinter wohl unterschiedliche Entwicklerteams stecken. Das zeigt sich an vielen Kleinigkeiten.
Und auch an einer Funktion, die bisher nur dem Mining-Fluss-Entwickler zur Verfügung steht: "Bis zu diesem Schritt ausführen ...". Genial ...
Rechte Maustaste drücken auf einem Operator in Mining-Fluss und den Punkt im Kontextmenü auswählen. Der Rest ist selbstredend. Es können also beliebige Teilflüsse getestet werden, natürlich ohne dass der Mining-Fluss vollständig sein muss.
Dieses Feature wäre auch für das Erstellen und Test von Datenflüssen hilfreich. Wieder ein Feature für zukünftige DWE-Versionen.
Ich habe leider noch keinen einfachen Weg gefunden, um einen Operator auf dem Panel des Design Studios per Copy/Paste (mit dem Kontextmenü oder mit "Bearbeiten") oder per Drag-and-Drop zu kopieren.
Bei aufwändig gefüllten Operatoren wäre das schon eine große Hilfe. Es gibt aber da noch die XML-Dateien, die Daten-, Mining- oder Steuerungsflüsse beschreiben. Mit etwas Aufwand, lässt sich die XML-Darstellung des begehrten Operators aus der Quelldatei kopieren und in die Zieldatei einfügen.
Es gibt aber einen schnelleren Weg, wenn nur Operatoren aus einem Fluss kopiert werden sollen: Kopiere als Erstes den gesamten Fluss im Projektexplorer mit dem Kontextmenu und lösche alle nicht gebrauchten Operatoren.
Trotzdem: Copy, Cut und Paste für definierte Operatoren wären ein hübsches Feature für eine der 9.1-Nachfolgeversionen.
Wednesday, 25. October 2006
Eigentlich sollte ich mich nicht durch Oracle's Marketinggetue provozieren lassen. Performance als das Thema der Oracle 11g, erstmals schneller als spezialisierte Dateisysteme? Beeindruckend?
Sicher nicht, solange Oracle mit seinem Vergleich mehr Fragen aufwirft als Antworten gibt. Gegen welches Filesystem wurde gemessen? Woher kamen die Daten aus der Datenbank? Von einem Raw Device oder gar aus dem Cache? Letzteres wäre schon fast Betrug.
Trotzdem: Es ist ja bekannt, dass Oracle Marketing schon oft mehr versprochen hat, als Oracle Software halten konnte.
Also: Abwarten und auf die Details zu den versprochenen Performance-Verbesserungen abwarten. Und dann gibt es ja noch TPC.
Das Gleiche gilt für die Aussagen zur verbesserten Kompression in der 11g.
Und wie sieht es mit insgesamt 482 neuen Features aus? Beeindruckend? "Mit wie vielen kann man wirklich was anfangen?" fragte Bernd.
Also: Abwarten und auf die Liste der Neuerungen warten.
Eine Neuerung scheint aber zu fehlen: Die konsequente Integration von XML so, wie es DB2 9 vermag. Es sieht also so aus, dass die armen, unschuldigen XML-Dokumente weiterhin vor der Speicherung in eine Oracle-Datenbank zerrissen und zerfetzt werden.
Tuesday, 24. October 2006
Während ich mich gestern abend, kurz vor Mitternacht, noch mit Pivot-Tabellen (nein, nicht mit Excel) beschäftigte, poppte mein Feed-Reader mit der Meldung " Oracle releases 11g database beta" noch. Überraschung! Verursacher ist ein Beitrag in "The Register" von gestern, 20.35 GMT.
Danach verbessert Oracle mit der 11g seine Kompressionstechnik. Man darf gespannt darauf sein, was genau dahinter steckt, und wie die Oracle-Kompression nun im Vergleich zu der von DB2 9 ausfällt.
Im IDG-Testbericht zur DB2 9 vermerkte der Redakteur zum Thema " Kompression":
"All the same, if I had to pick one feature that puts DB2 ahead of any of the other databases, this would definitely be the one, because it's going to be far more useful to the largest portion of the client base. I would imagine that Oracle and Microsoft are both scrambling to be the next to bring this to market."
Schafft also Oracle den Anschluß noch vor Microsoft?
|
 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.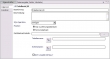 In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE.
In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE. 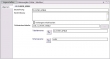 Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".
Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".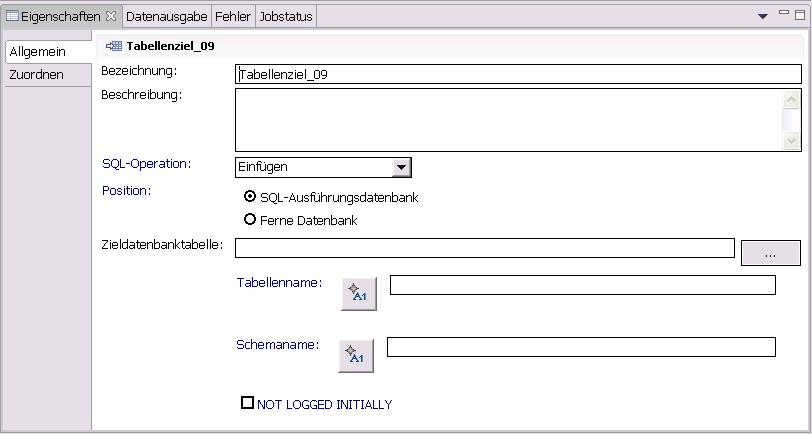
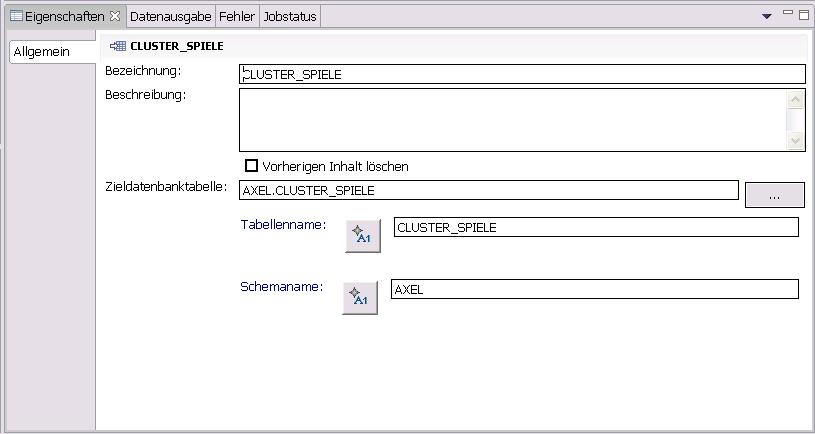
 Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.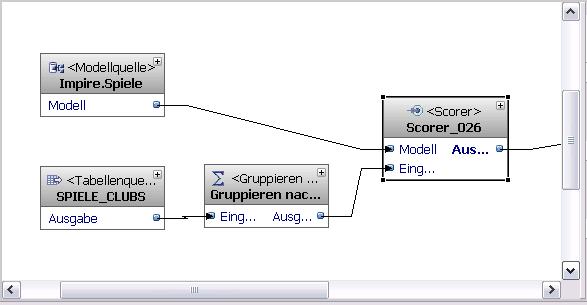

 ap127
ap127