Sunday, 29. October 2006
Noch mehr zum Thema " Jeder Fluss ist anders".
Gleicher Namen heißt nicht gleicher Inhalt. Das gilt auf jeder Fall für den Tabellenziel-Operator im Daten- und im Mining-Fluss.
In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE.
Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".
Diese Option wäre IMO auch für den gleichnamigen Operator im Daten-Fluss sinnvoll. Dann muss ich nicht im Falle eines Inserts bereits exsistierende Daten explizit per Operator löschen. Dies würde unter Umständen zur Synchronisation sogar einen Steuerungs-Fluss erfordern.
Dafür könnte im Gegenzug der Operator im Mining-Fluss die Check-Box "NOT LOGGED INITIALLY" erhalten oder gar den Tab "Zuordnen". Give 'n Take.
Von Mining-Operatoren wie z.B. dem "Clusterer" werden automatisch Mining-Modelle erstellt und in der Datenbank gespeichert. So ein Modell kann dann im Scorer ausgewählt werden. Bei dieser Auswahl kann man dann sehen, welche Modelle überhaupt erstellt wurden. Da war dann in meinem Fall noch das eine oder andere experimentelle Modell darunter.
Nur, wo kann ich solche nicht verwendete Modelle löschen. Oder allgemeiner: Wo kann ich Mining-Modelle verwalten?
Einfache Frage, einfache Antwort: In der Ausführungsdatenbank und dort in der Tabelle IDMMX.CLUSTERMODELS. Dies ist übrigens eine der Tabellen, die beim " Enable for Data Mining" angelegt werden.
Zur Verwaltung der Modelle steht also der komplette SQL-Funktionsumfang zur Verfügung.
Trotz alles SQL-Möglichkeiten wäre es sicher sinnvoll, wenn Mining-Modelle direkt im Design Studio in bewährter Art und Weise verwaltet werden könnten (23.11.2006: was auch tatsächlich angeboten wird, wenn auch an etwas unerwarteter Stelle).
Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Eine der hilfreichsten von vielen nützlichen Funktionen im Design Studio ist "In Modell speichern". Sie ist jeweils unter "Virtuelle Tabelle" in den Eigenschaften der Ein- und Ausgabeports verfügbar. So kann ganz einfach eine durch einen Operator erstellte Ausgabe sofort im Modell als Tabelle widerspiegelt werden. Diese Tabelle kann ich dann z.B. als Tabellenziel am Ende des Flusses verwenden.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Um das alles ein wenig abzukürzen: Im Falle des Scorer geht das schief.
"Schiefgagangen" vollständig lesen
Hier sind zwei der Kleinigkeiten, die mir das Entwickeln eines Minig-Flusses erleichtern:
Friday, 27. October 2006
Ein Fluss muss nicht wie der andere sein.
Zumindest ist das im Design Studio recht offensichtlich. Hat man einige Datenflüsse und Minig-Flüsse erstellt, sieht man recht schnell, dass dahinter wohl unterschiedliche Entwicklerteams stecken. Das zeigt sich an vielen Kleinigkeiten.
Und auch an einer Funktion, die bisher nur dem Mining-Fluss-Entwickler zur Verfügung steht: "Bis zu diesem Schritt ausführen ...". Genial ...
Rechte Maustaste drücken auf einem Operator in Mining-Fluss und den Punkt im Kontextmenü auswählen. Der Rest ist selbstredend. Es können also beliebige Teilflüsse getestet werden, natürlich ohne dass der Mining-Fluss vollständig sein muss.
Dieses Feature wäre auch für das Erstellen und Test von Datenflüssen hilfreich. Wieder ein Feature für zukünftige DWE-Versionen.
Ich habe leider noch keinen einfachen Weg gefunden, um einen Operator auf dem Panel des Design Studios per Copy/Paste (mit dem Kontextmenü oder mit "Bearbeiten") oder per Drag-and-Drop zu kopieren.
Bei aufwändig gefüllten Operatoren wäre das schon eine große Hilfe. Es gibt aber da noch die XML-Dateien, die Daten-, Mining- oder Steuerungsflüsse beschreiben. Mit etwas Aufwand, lässt sich die XML-Darstellung des begehrten Operators aus der Quelldatei kopieren und in die Zieldatei einfügen.
Es gibt aber einen schnelleren Weg, wenn nur Operatoren aus einem Fluss kopiert werden sollen: Kopiere als Erstes den gesamten Fluss im Projektexplorer mit dem Kontextmenu und lösche alle nicht gebrauchten Operatoren.
Trotzdem: Copy, Cut und Paste für definierte Operatoren wären ein hübsches Feature für eine der 9.1-Nachfolgeversionen.
Wednesday, 25. October 2006
Eigentlich sollte ich mich nicht durch Oracle's Marketinggetue provozieren lassen. Performance als das Thema der Oracle 11g, erstmals schneller als spezialisierte Dateisysteme? Beeindruckend?
Sicher nicht, solange Oracle mit seinem Vergleich mehr Fragen aufwirft als Antworten gibt. Gegen welches Filesystem wurde gemessen? Woher kamen die Daten aus der Datenbank? Von einem Raw Device oder gar aus dem Cache? Letzteres wäre schon fast Betrug.
Trotzdem: Es ist ja bekannt, dass Oracle Marketing schon oft mehr versprochen hat, als Oracle Software halten konnte.
Also: Abwarten und auf die Details zu den versprochenen Performance-Verbesserungen abwarten. Und dann gibt es ja noch TPC.
Das Gleiche gilt für die Aussagen zur verbesserten Kompression in der 11g.
Und wie sieht es mit insgesamt 482 neuen Features aus? Beeindruckend? "Mit wie vielen kann man wirklich was anfangen?" fragte Bernd.
Also: Abwarten und auf die Liste der Neuerungen warten.
Eine Neuerung scheint aber zu fehlen: Die konsequente Integration von XML so, wie es DB2 9 vermag. Es sieht also so aus, dass die armen, unschuldigen XML-Dokumente weiterhin vor der Speicherung in eine Oracle-Datenbank zerrissen und zerfetzt werden.
Tuesday, 24. October 2006
Während ich mich gestern abend, kurz vor Mitternacht, noch mit Pivot-Tabellen (nein, nicht mit Excel) beschäftigte, poppte mein Feed-Reader mit der Meldung " Oracle releases 11g database beta" noch. Überraschung! Verursacher ist ein Beitrag in "The Register" von gestern, 20.35 GMT.
Danach verbessert Oracle mit der 11g seine Kompressionstechnik. Man darf gespannt darauf sein, was genau dahinter steckt, und wie die Oracle-Kompression nun im Vergleich zu der von DB2 9 ausfällt.
Im IDG-Testbericht zur DB2 9 vermerkte der Redakteur zum Thema " Kompression":
"All the same, if I had to pick one feature that puts DB2 ahead of any of the other databases, this would definitely be the one, because it's going to be far more useful to the largest portion of the client base. I would imagine that Oracle and Microsoft are both scrambling to be the next to bring this to market."
Schafft also Oracle den Anschluß noch vor Microsoft?
Monday, 23. October 2006
Diese Ankündigung habe ich noch nicht bei ibm.com gefunden. Daher gibt es hier auch keinen Link, und daher konnte ich keine Details nachsehen. Einige Fragen bleiben also offen, spätestens bis ich die Version 9.1.1 installiert habe.
Das wird dann auch nicht mehr solange auf sich warten lassen: am 1.12. steht der Refresh zum Download bereit, also noch im 4.Quartal, so wie prognostiziert.
Die wesentliche Neuerung dieser Hundertstel-Version ist die Einbindung der aktuellen DB2-Version 9.1. Dies hätte möglicherweise auch mit der DWE 9.1 funktioniert, aber mit der 9.1.1 ist es nun offiziell. Und man weiß ja nie, was so passieren kann.
Damit stehen nun der DWE alle neuen Features der DB2 9 wie
- Self-Tuning Memory Management
- Table (Range) Partitioning und
- Table (Row) Compression
zur Verfügung. So zu lesen in der Ankündigung. Mal sehen, wie sich dies im SQW niederschlägt.
... hat IBM nach eigenen Aussagen in die Entwicklung von DB2 9 gesteckt. In Sachen Performance scheint sich diese Investition gelohnt zu haben, zumindest aus Sicht des Marketings. Danach hält DB2 9 nun eine dreifache Benchmark-Krone:
"A key measure of the impact that these new technologies are having is the “big three” industry benchmark records (TPC-C, TPC-H and SAP SD) – collectively known as the Database performance triple crown."
...
"IBM today announced that with the introduction of DB2 9 it has set new record marks in each and has now won the “triple crown” of database performance for an unprecedented third time."
Für die TPC-Ergebnisse schlage man ebendort nach.
Das TPC-H-Ergebnis für DB2 9 scheint noch nicht veröffentlicht zu sein. Mal sehen, wann das erscheint.
Das TPC-C-Ergebnis kenne ich schon seit einigen Monaten. Auf den ersten Blick sieht es recht beeindruckend und eindeutig aus. Wenn man allerdings berücksichtigt, dass die Benchmarks auf jeweils unterschiedlicher Hardware gefahren wurden, relativiert sich der eine oder andere deutliche Vorsprung in Sachen reiner Performance.
Man sieht aber auf jeden Fall, dass DB2 9 in Sachen TPC-C besser performt als Oracle 10g.
Gerade im Vergleich mit Oracle wäre ein IDS-Benchmark spannend.
Anlässlich der "Information on Demand"-Konferenz verkündet IBM erste Erfolge bei der Kundengewinnung mit DB2 9.
"Hundreds of customers across different industries have already embraced DB2 9 and many are moving their databases from Oracle to IBM’s new data server, including: American Electric Power, Central Michigan University, Farmers Insurance and Teleglobe." Dabei sollen vor allem die neue Features wie Kompression und XML-Unterstützung für den Sinneswandel ausschlaggebend gewesen sein.
Ich bin bei solchen Meldungen erst mal skeptisch. Erfolge im Wettbewerb werden langfristig in Zu- oder Abnahme von Marktanteilen gemessen. Warten wir also die nächsten Gartner- oder IDC-Studien ab. Auch wenn ich von diesen Studien nicht viel halte, Bewegungen am Markt werden sie hinreichend reflektieren.
Sicher, die neuen Features von DB2 9 sind aus technischer Sicht überzeugend, aber reicht das, um alte, eingeschworene Oracle-Anwender zu einer in der Regel aufwändigen Migration zu bewegen?
Ob DB2 9 auch aus geschäftlicher Sicht gegen Oracle überzeugt, wird wohl mühsam im Einzelfall in PoCs nachgewiesen werden müssen.
Sunday, 8. October 2006
Es ist tatsächlich nicht so, dass die IT-Presse nicht lernfähig wäre. Einige Monate nach dem katastrophalen Ausrutscher des CW-Ressortleiters ue, hat die CW indirekt die Aussagen ihrer "Kenner der Datenbankszene" revidiert.
Die CW-Muttergesellschaft IDG hatte die neue DB2-Version in ihrem Labor getestet und für hervorragend befunden.
So purzeln nun wie selbstverständlich folgende absolut korrekte Erkenntnisse aus der CW-Feder:
"Statt wie bisher XML als Blob (Binary Large Object) zu speichern oder XML-Struktur auf relationale Strukturen abzubilden, speichert pureXML die XML-Datei selbst - mit all ihren Eigenschaften und ihrer hierarchischen Struktur."
Na also, das habe ich ja schon immer gesagt.
Als erstes Resultat seiner Zusammenfassung der IDG-Testergebnisse kommt der Autor (ba) zu einem erfreulichen Ergebnis:
"Alles in allem ist die neue DB2 technisch imposant. Sie ist voll gestopft mit Funktionen, die Administratoren und Entwickler gleichermaßen freuen." Aber das ist noch nicht alles ...
Saturday, 7. October 2006
Bei neuer Software sollte man schon mal ins Handbuch schauen. Das Design Studio der DWE ist neu, das "Handbuch" ist sehr umfangreich - ganz entsprechend der Funktionsvielfalt der dokumentierten Anwendung. Ich war eben wieder mal lesefaul. Also muss ich nun Abbitte leisten:
Da habe ich mich doch vor Zeiten beschwert, dass sich im Datenimport-Operator Feldtrenner und Zahlenformat nicht aus einer Liste bequem auswählen lassen.
So sind als Trenner unter Eigenschaften/Dateiformat STANDARD, TAB, ", %, das Komma und anderes selektierbar, wobei unter STANDARD das Komma verstanden wird. Eine Drop-down-Liste für Zahlenformate ist erst gar nicht vorgesehen. Also habe ich unwissend, wie ich nun mal war, die Quelldatei entsprechend aufbereitet - mit Komma als Feldtrenner und dem angelsächsischen Dezimalpunkt.
Hätte ich nur in der Doku oder im Tool-Tip nachgeschaut, was ich alles unter "Zusätzliche Dateitypmodifikatoren" eintragen kann. Das ist immerhin ein MLE mit viel Platz für alle möglichen Optionen, so z.B. für
modified by coldel; decpt,
(oder einfach: coldel; decpt, )
Und genau hätte mein Problem gelöst. Zwar nicht per Auswahl aus einer Drop-down-Liste, aber immerhin.
Dadurch wird der NLS nicht vollständig, aber ich hatte da tatsächlich was übersehen.
|
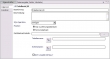 In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE.
In einem Daten-Fluss kann dieser Operator die Daten aus dem Eingabeport in die Zieltabelle einfügen, oder Daten in der Zieltabelle aktualisieren oder löschen - aber nur eines zur Zeit. Dahinter stecken die SQL-Anweisungen INSERT, UPDATE oder DELETE. 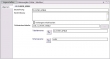 Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".
Der Tabellenziel-Operator im Mining-Fluss kann dagegen Daten nur einfügen, dafür besitzt er aber die Check-Box "Vorherigen Inhalt löschen".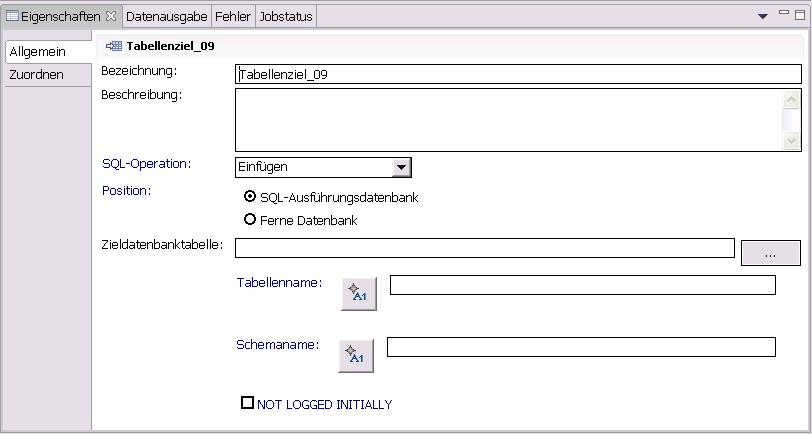
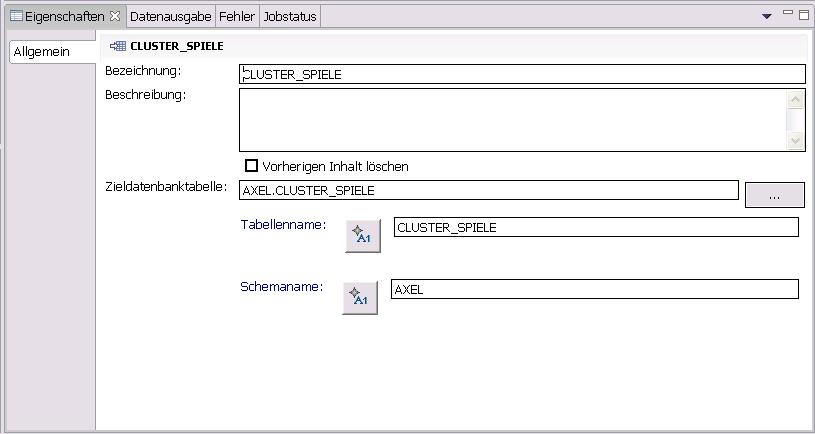
 Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.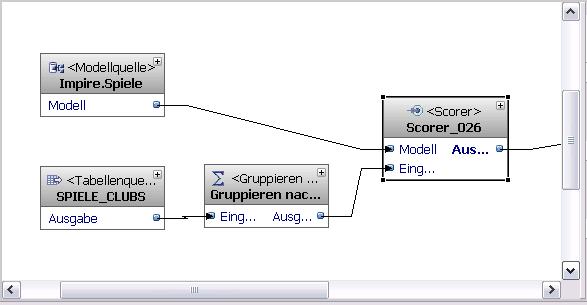

 ap127
ap127